New suite of features enables analysis of amplicon and geochemistry data

We’re releasing a suite of features that will allow researchers to integrate their biological and geochemistry data to gain new insights about the relationship between microorganisms and their environment. You can now import environmental sampling data into KBase in ways that allow analysis of biogeochemistry and diversity. These improvements capture all 3 – import of sample metadata, biogeochemistry derived from those samples, as well as amplicon-based sequence data. With these new data types and enhanced functionality, you can profile taxonomy from amplicon data and correlate geochemistry with OTU abundance across all of your sampling conditions.
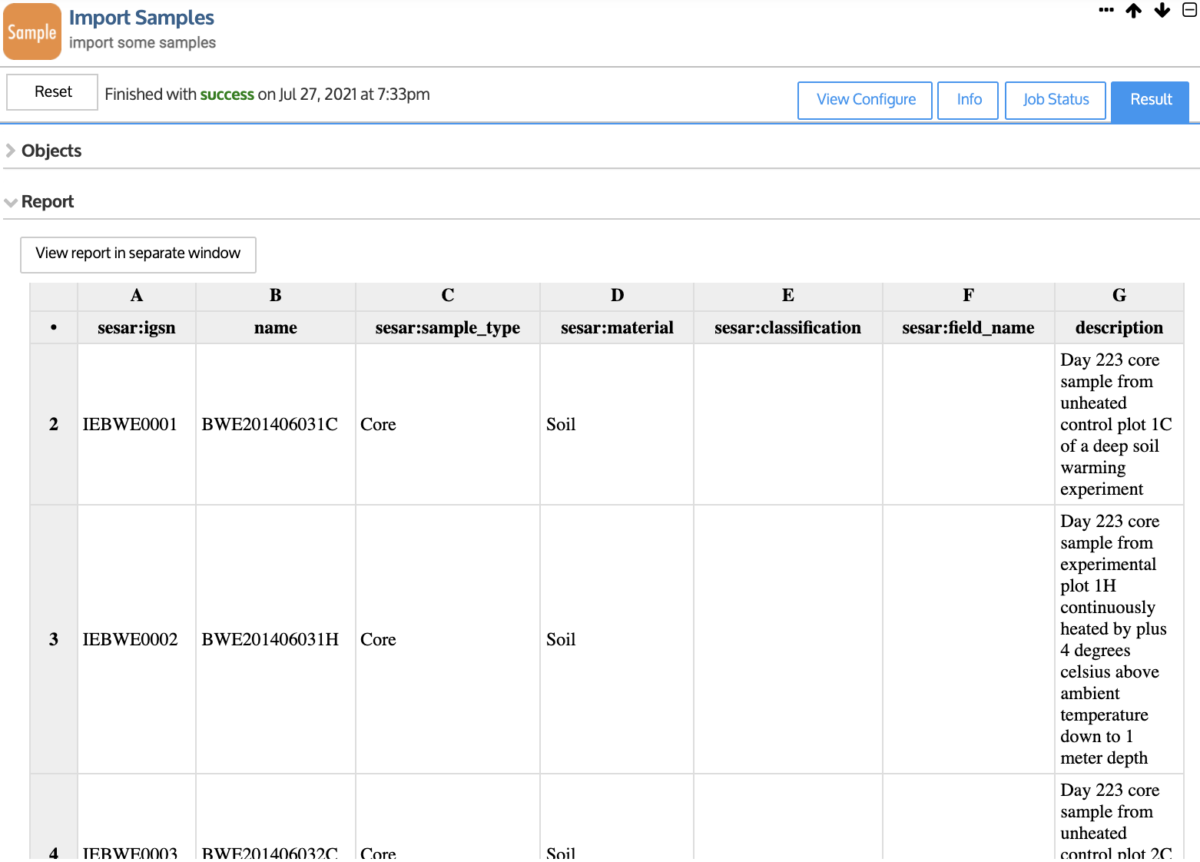
Import Samples into KBase
New importers allow you to add amplicon sequencing data as an AmpliconMatrix, environmental chemistry tables as a Chemical Abundance Matrix, and tables of conditions from your experimental samples as a SampleSet into your KBase Narratives. Think of a SampleSet as the foundation for your experimental data, used for organizing and contextualizing your experiments, and establishing relationships to additional layers of biological data. For this initial release, the KBase team designed the foundation to be compatible with public data infrastructure projects serving environmental sciences research communities. If you have data in the System for Earth Sample Registration (SESAR) or Environmental Systems Science Data Infrastructure for a Virtual Ecosystem (ESS-DIVE), you should be able to upload your experimental data seamlessly with our importers tailored for these table formats. Once imported, you can view geolocation, collection information, and experimental metadata, as well as linkages to data in KBase.
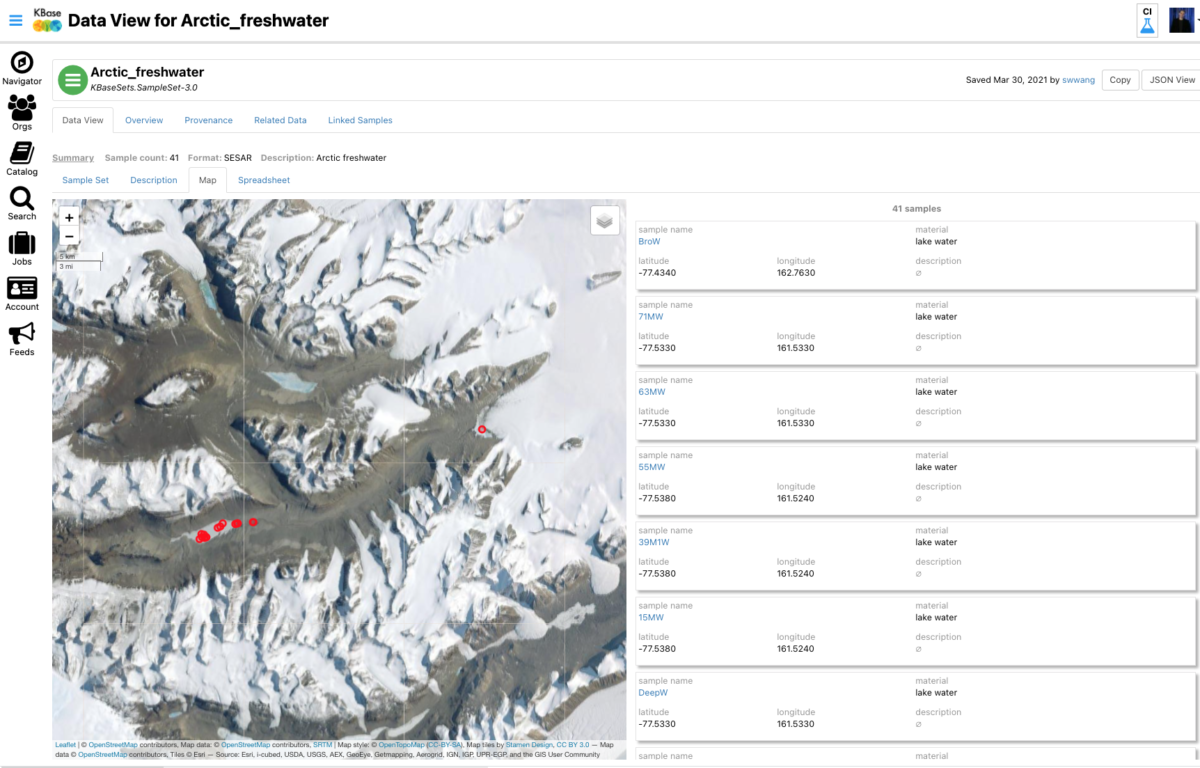
SampleSet data viewer
We are also releasing new apps that use AmpliconMatrix, Chemical Abundance Matrix, and SampleSet data for inferring relationships and drawing conclusions about your environmental sample. Generate Taxonomy Abundance Barplot computes and visualizes taxonomic abundances of OTUs from your amplicon data. Use the Compare Correlation Matrices app to correlate chemistry from an environmental sample with your OTU abundance profile.
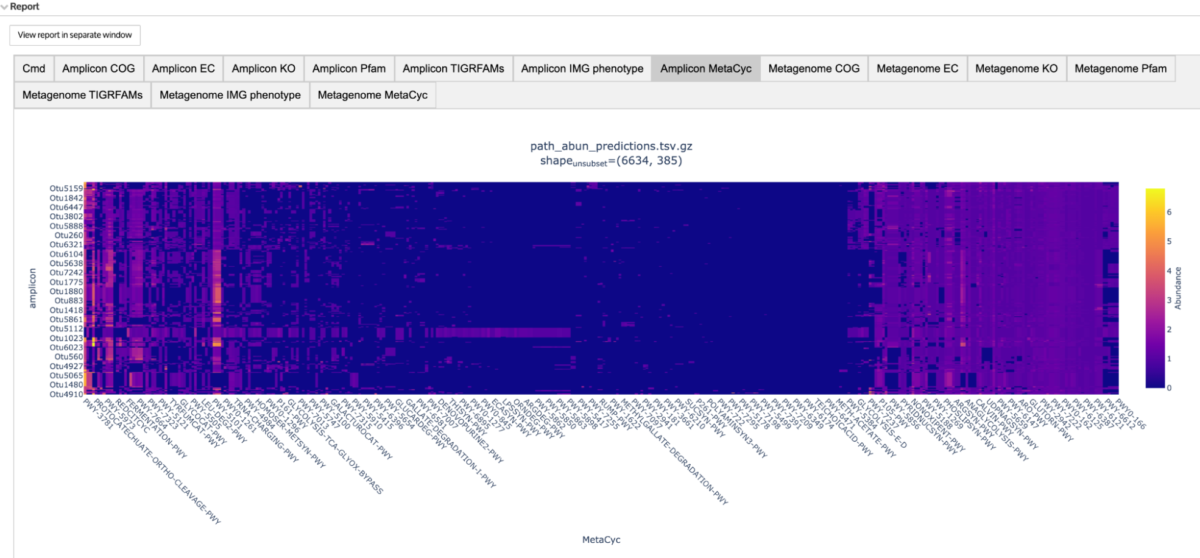
Correlating OTU abundance to environmental chemistry
These new features and apps represent the big first step towards the full breadth of analytical capabilities we are developing for exploring biological and environmental data in KBase. Combined, these advancements make a strong foundation for performing robust systems biology analysis across heterogeneous data using the KBase infrastructure and platform. We’ll be hosting webinars over the coming weeks to introduce and demonstrate these new features to the KBase community. Sign up using the links below:
- Introducing Samples in KBase – September 29
- Samples Upload in KBase – October 13
Interested in helping us design and test new features? Sign up to become a KBase tester! If you have questions or requests about any of these new features, please join our Help Board and post a ticket: http://kbase.us/support
Added features:
- New Data Type: SampleSet
- New Data Type: AmpliconMatrix
- New Importer: Import Samples
- New Importer: Import Amplicon Matrix from TSV/FASTA File in Staging Area
- New Importer: Import Chemical Abundance Matrix from CSV/Excel/TSV File in Staging Area
- New App: Generate Taxonomy Abundance Barplot
- New App: Compare Correlation Matrices









