Community Highlight: FAIR Data at ASM Microbe
Dr. Ellen Dow (KBase, Lawrence Berkeley National Laboratory) and Dr. Vanja Klepac-Ceraj (Wellesley College) held a Lounge & Learn at the American Society for Microbiology Microbe Meeting on Saturday June 21 that covered:
- The FAIR data principles:
- Findable – data given a registered and unique persistent identifier,
- Accessible – retrievable using a standard protocol,
- Interoperable – machine readable through widely used file formats, and
- Reusable – detailed provenance and processing information;
- Why researchers should adhere to the FAIR principles; and
- How researchers can use KBase and ASM’s Microbiology Research Announcements (MRA) to efficiently and effectively make data FAIR.

Drs. Vanja Klepac-Ceraj and Ellen Dow opening the Lounge & Learn session. (Photo courtesy of Dr. Jonelle Basso)
The FAIR data principles
FAIR – Findable, Accessible, Interoperable, Reusable – is a set of principles put forth almost 10 years ago by Wilkinson et al. (2016). The FAIR data principles recommend features and attributes that can be added to data as useful context for researchers and machines to discover and reuse the data. Many at the Lounge & Learn session were familiar with the FAIR principles, but to some FAIR was still new. However, even with an audience familiar with the FAIR principles, the application of these principles is still an important, and evolving, discussion in the microbiology community.
Infrastructure for FAIR data
Persistent Identifiers (PIDs) help build an infrastructure for FAIR data. Often under-utilized, the architecture of PIDs connects the people, organizations, and products within a project (Fig. 1). Projects can contain multiple research products, including samples, datasets, software, publications, which can be assigned PIDs to link them together and back to the individual researcher(s) and project. These can be described within a Data Management Plan (DMP), that can also have its own PID.
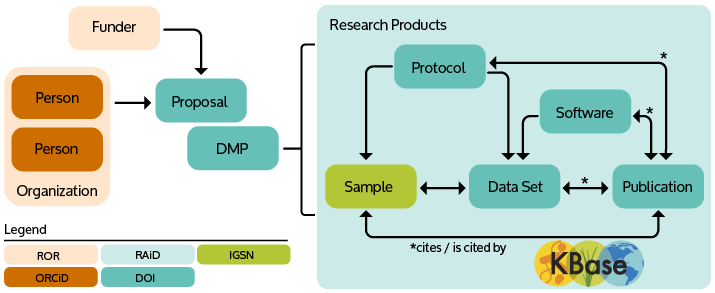
Figure 1. Using persistent identifiers (PID) to link organizations and researchers to the overall research project and products.
Why use the FAIR principles?
Data is often not shared because of real and perceived challenges, including knowledge barriers, reuse concerns, and disincentives to share data openly (Gomes et al. 2022). The process can be ambiguous, shared data may be misinterpreted, and credit for data reuse isn’t always given. However, the guidelines outlined in the FAIR data principles can ensure data is reusable and citable by the community. By applying the infrastructure in Figure 1, research products can be linked together and referenced within publications to provide the proper context for reuse, resulting in more citations and increased data impact when the community follows these as a whole.
Breaking down acronyms
FAIR – findable, accessible, interoperable, reusable
DMP – data management plan
ROR – research organization registry
ORCiD – open researcher and contributor identifier
RAiD – research activity identifier
DOI – digital object identifier
IGSN – international geo/general sample number
KBase tracks data provenance and integrates external resources to ensure research products are FAIR, visible, and trackable. Anyone can request a DOI for their static Narrative to cite within publications and track dataset metrics to understand how the KBase community uses published data.
Making Data FAIR with ASM MRA
But infrastructure only goes so far to make data reusable. In addition to PIDs, domain-specific metadata that describes the context around data collection and processing (i.e., sample environment or laboratory conditions) make data comparable and increase the potential of reuse (Wood-Charlson et al. 2022). ASM’s Microbiology Resource Announcements (MRA) promotes best practices of data sharing and reuse beyond FAIR principles. Data shared through MRA meets the requirements for reproducibility and reuse, more than solely uploading a dataset to a repository (though that is also required for MRA!). MRA data publications are peer-reviewed, completely online and open access, and utilize a straightforward submission process with easy to follow checklists.
Looking for support?
Curious about how KBase is working to measure the impact of your data analysis efforts, beyond publications? Contact us at engage@kbase.us.
References & Links
Gomes DGE, Pottier P, Crystal-Ornelas R, Hudgins EJ, Foroughirad V, Sánchez-Reyes LL, Turba R, Martinez PA, Moreau D, Bertram MG, Smout CA. and Gaynor KM. Why don’t we share data and code? Perceived barriers and benefits to public archiving practices. Proceedings of the Royal Society B (2022) 28920221113. http://doi.org/10.1098/rspb.2022.1113
Wood-Charlson EM, Crockett Z, Erdmann C, Arkin AP, Robinson CB. simple rules for getting and giving credit for data. PLOS Computational Biology (2022) 18(9): e1010476. https://doi.org/10.1371/journal.pcbi.1010476
Resources
MRA author checklist: https://journals.asm.org/pb-assets/pdf-text-excel-files/MRA-Author-Checklist-1673638757867.pdf
KBase MRA Template, Isolates: https://narrative.kbase.us/narrative/122280
KBase MRA Template, MAGs: https://narrative.kbase.us/narrative/126611
Promoting Microbiome Workforce Development with KBase Collection: https://journals.asm.org/journal/mra/kbase

